
Guia prático de Ciência de dados para iniciantes
A Ciência de dados é um campo em constante expansão, caracterizado por sua natureza multidisciplinar que utiliza métodos, processos, algoritmos e sistemas científicos para extrair conhecimento e insights de dados estruturados e não estruturados. Nos últimos anos, essa área tem testemunhado um crescimento exponencial, alimentado pelo interesse crescente em suas aplicações em uma variedade de setores.
Este artigo se propõe a ser mais do que apenas um guia básico; é um recurso abrangente para aqueles que estão prestes a mergulhar no vasto mundo da Ciência de dados.
Breve histórico da Ciência de dados
A Ciência de dados é uma área relativamente nova, surgida no início do século XXI em resposta à crescente quantidade de dados gerados pela tecnologia da informação. Suas raízes, no entanto, podem ser rastreadas até o século XVIII, quando a estatística começou a se desenvolver como uma disciplina matemática fundamental para a análise de dados em diversos setores, como finanças, saúde e ciências sociais.
A estatística emerge como disciplina matemática, fornecendo ferramentas essenciais para a compreensão e gestão de dados. A revolução industrial impulsionou a produção de dados, especialmente em finanças e contabilidade. A análise estatística se tornou crucial. No final do século XX, a era da informação traz uma explosão na geração de dados, dificultando sua gestão e análise com ferramentas tradicionais. Nos anos 90, a internet e a World Wide Web geram dados massivos por meio de sites de comércio eletrônico, redes sociais e aplicativos web. O desenvolvimento da Ciência de dados é liderado por estatísticos e especialistas em matemática aplicada para lidar com grandes conjuntos de dados. No século XXI, a ciência de dados se consolida como disciplina independente, focada em extrair insights significativos de dados. Avanços tecnológicos como o Apache Hadoop (2006) e técnicas como Machine Learning (ML) e Deep Learning (DL) impulsionam sua evolução.
Fundamentos da Ciência de dados
A palavra “Ciência de dados” tornou-se bastante comum. Mas o que isso realmente significa? Quais habilidades são necessárias para se tornar um Cientista de dados? Qual a diferença entre Business Intelligence e Data Science? Como funcionam as tomadas de decisão e previsões em Ciência de dados? Aqui estão algumas das perguntas que tentaremos responder. Vamos começar com o básico.
Qual é a definição de “Ciência de dados”?
Já abordámos algumas palavras na introdução. Muito esquematicamente, poderíamos dizer que a Ciência de dados mistura ferramentas, algoritmos e princípios de aprendizado de máquina com o objetivo de descobrir padrões ocultos a partir de dados brutos. Mas como o trabalho do cientista de dados é diferente do que os analistas de dados vêm fazendo há anos? A diferença entre os dois se resume à diferença entre explicar e prever.
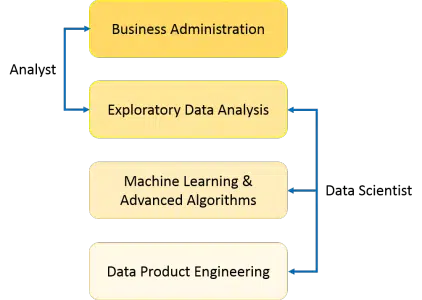
O papel do analista de dados é explicar o que está acontecendo através da exploração dos dados disponíveis. Por outro lado, o cientista de dados vai além da análise exploratória, empregando também algoritmos avançados de ML para identificar ocorrências futuras de eventos específicos. Ele examina os dados sob múltiplos prismas, revelando perspectivas anteriormente desconhecidas. A ciência de dados é fundamentalmente aplicada na tomada de decisões e na realização de previsões, valendo-se da análise preditiva causal, da análise normativa e do ML.
Vamos nos aprofundar em cada um desses conceitos:
Análise causal preditiva: Se deseja construir um modelo capaz de prever a probabilidade de ocorrência de eventos futuros, é necessário recorrer à análise preditiva causal. Por exemplo, em setores como empréstimos financeiros, determinar se os clientes cumprirão com os pagamentos dentro do prazo é uma preocupação crítica. Nesse caso é possível criar um modelo para realizar análises preditivas e antecipar se os clientes honrarão suas obrigações com base em seu histórico de pagamentos.
Análise normativa: Se almeja um modelo com inteligência para tomar decisões autônomas e adaptáveis com base em parâmetros dinâmicos, então a análise normativa é indispensável. Este campo emergente visa gerar recomendações. Por exemplo, em veículos autônomos, os dados coletados podem ser utilizados para treinar esses automóveis, permitindo que algoritmos sugiram diversas ações com base em resultados previsíveis, como virar, acelerar ou desacelerar.
Machine Learning (para tomada de decisão): Se possui dados transacionais à disposição e busca construir um modelo para identificar tendências futuras, o ML é a escolha ideal. Esse método, conhecido como aprendizado supervisionado, utiliza dados prévios para treinar algoritmos. Por exemplo, é possível desenvolver um modelo de detecção de fraudes utilizando o histórico de transações fraudulentas.
Machine Learning (para descobrir padrões): Quando não há parâmetros prévios para fazer previsões antecipadas, é necessário encontrar padrões ocultos explorando o banco de dados. Isso é realizado através de modelos não supervisionados. Por exemplo, em uma empresa de telecomunicações, pode-se aplicar técnicas de agrupamento para determinar o posicionamento ideal das torres de transmissão, visando oferecer o melhor sinal aos usuários.
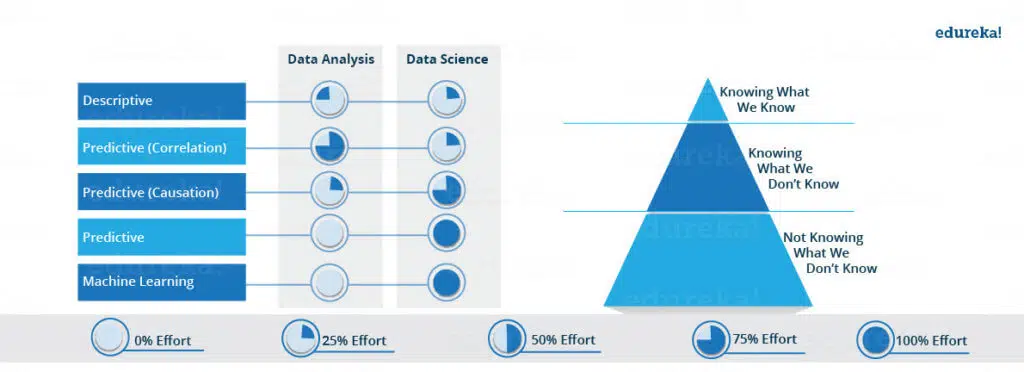
O infográfico abaixo fornece uma boa compreensão das diferenças entre Análise de dados e Ciência de dados, bem como sua sobreposição em certos aspectos. De fato, a análise de dados não está apenas na descrição. Incorpora uma dimensão preditiva até certo ponto (correlações). Na Ciência de dados, há muita análise preditiva e muito aprendizado de máquina.
Embora seja importante distinguir entre Análise de dados e Ciência de dados, é igualmente importante não confundir Ciência de dados e Business Intelligence. Estamos claramente falando de duas coisas diferentes:
O Business Intelligence (BI) é a atividade de analisar dados de negócios existentes para descobrir insights para ajudar os tomadores de decisão a tomar decisões. O BI usa dados externos e internos, prepara-os, consulta-os e cria dashboards para gestores ou tomadores de decisão. O BI também pode ser usado para realizar estudos de impacto.
A Ciência de dados é uma abordagem muito mais preditiva. Essencialmente, trata-se de explorar, analisar dados passados e presentes para prever resultados futuros. A Ciência de dados permite que você responda a perguntas abertas (“Como…?”, “O que…?”).
Veja as principais diferença entres as duas atividades:
| Business Intelligence | Ciência de dados | |
|---|---|---|
| Fonte de dados | Dados estruturados (SQL, Data Warehouse) | Dados estruturados e não estruturados (logs, dados em nuvem, SQL, NoSQL, texto) |
| Aproximação | Estatística e visualização | Estatística, Machine Learning, Análise de grafos, Processamento de Linguagem Natural (NLP) |
| Foco | Passado e presente | Presente e futuro (preditivo) |
| Ferramentas | Power BI, Qlik Sense, Tableau, Looker, Google Data Studio | TensorFlow, PyTorch, Apache Spark, Scikit-learn |
Ferramentas e tecnologias
Python: Amplamente adotada na Ciência de dados, Python é uma linguagem de programação que oferece bibliotecas poderosas como Pandas, NumPy e SciPy, facilitando a manipulação e análise de dados.
Linguagem R: Outra linguagem popular na Ciência de dados, o R oferece pacotes para manipulação, análise e visualização de dados, além de funções estatísticas avançadas.
SQL (Structured Query Language): Essencial para consultar e manipular bancos de dados relacionais, o SQL permite extrair informações de grandes volumes de dados armazenados em bancos de dados.
Excel: o Excel continua sendo uma ferramenta valiosa para coleta e Análise de dados, oferecendo recursos como fórmulas, gráficos e tabelas dinâmicas.
GitHub: Fundamental para controle de versão e colaboração em projetos de Ciência de dados, o GitHub possibilita o compartilhamento de código e a colaboração entre equipes.
IDEs (Integrated Development Environments): IDEs como Jupyter Notebook, Visual Studio Code e RStudio oferecem recursos abrangentes para desenvolvimento e execução de código em Ciência de dados.
Plataformas de Big Data: Ferramentas como Hadoop e Spark são essenciais para lidar com grandes volumes de dados, permitindo processamento distribuído e análise escalável.
Bibliotecas de Machine Learning: Scikit-Learn, TensorFlow e PyTorch facilitam a criação e treinamento de modelos de ML.
Visualização de Dados: Ferramentas como Apache Spark permitem a criação de gráficos e visualizações para comunicar insights de dados de forma eficaz.
Bancos de Dados NoSQL: Para dados não estruturados, bancos de dados NoSQL como MongoDB e Cassandra são úteis na ciência de dados.
Essas ferramentas e tecnologias desempenham um papel crucial na coleta, análise e interpretação de dados, capacitando cientistas de dados a tomarem decisões estratégicas e gerarem insights valiosos.
Passos práticos para começar
Aprenda o básico de estatística e matemática
A Ciência de dados é baseada em conceitos estatísticos e matemáticos básicos. Entender esses conceitos é essencial para o sucesso na área. Comece aprendendo os conceitos básicos de estatística e probabilidade, incluindo média, mediana, modo e desvio padrão. Em seguida, passe para matemática, álgebra linear e otimização.
Aprender uma linguagem de programação
A Ciência de dados é um campo que depende muito da programação, por isso é essencial ser proficiente em pelo menos uma linguagem de programação. Python e R são as linguagens mais populares para ciência de dados, mas você também pode usar outras linguagens, como Java ou C++.
Aprenda os conceitos básicos de visualização de dados
A visualização de dados é uma parte essencial da Ciência de dados, por isso é importante entender como visualizar dados. Comece aprendendo os fundamentos da visualização de dados usando ferramentas como matplotlib e seaborn em Python ou ggplot em R.
Aprenda os conceitos básicos de ML
O ML é um subconjunto da IA que permite que as máquinas aprendam com os dados sem serem explicitamente programadas. Comece aprendendo os fundamentos da aprendizagem supervisionada e não supervisionada, incluindo algoritmos de aprendizagem supervisionada, como regressão linear e logística, e algoritmos de aprendizagem não supervisionada, como agrupamento k-means.
Pratique conjuntos de dados
Depois de entender os conceitos básicos de Ciência de dados, é importante praticar com conjuntos de dados do mundo real. Kaggle é uma ótima plataforma que oferece uma ampla variedade de conjuntos de dados e desafios para trabalhar.
Obtenha a Certificação
Uma certificação pode ajudá-lo a se destacar no mercado de trabalho e demonstrar seu conhecimento em ciência de dados para potenciais empregadores. Existem vários programas de certificação em ciência de dados disponíveis online, como os oferecidos pelo Coursera, Google, Microsoft e entre outros.
Em nosso artigo: 20 cursos gratuitos de Data Science, você confere alguns cursos mencionados acima.
Junte-se a uma comunidade
Juntar-se a uma comunidade de cientistas de dados pode ajudá-lo a aprender com outras pessoas e manter-se atualizado sobre as últimas tendências e desenvolvimentos no campo. Existem várias comunidades online, como Data Hackers, R-Ladies e Reddit, onde você pode se conectar com outros Cientistas de dados.
Aprender Ciência de dados do zero leva tempo e esforço, mas é um processo gratificante que pode levar a uma carreira em um campo empolgante e com alta demanda de profissionais. Seguindo as etapas descritas neste guia, você pode obter o conhecimento e as habilidades necessárias para se tornar um Cientista de dados.
Conclusão
Em conclusão, exploramos os fundamentos e avanços da Ciência de dados, desde suas origens até sua evolução como disciplina independente. Ao longo deste artigo, destacamos a importância da estatística, Machine Learning e análise de dados na Ciência de dados, delineando as diferenças entre análise de dados e Business Intelligence. Embora o caminho para se tornar um cientista de dados possa ser desafiador, é também incrivelmente gratificante. Com dedicação e perseverança, você será capaz de adquirir as habilidades necessárias para uma carreira promissora.