
Como facilitar o processamento de dados com Apache Hadoop?
O Hadoop é uma plataforma de código aberto que foi criada para armazenar e processar grandes volumes de dados. Ele funciona dividindo os dados em blocos e distribuindo-os em vários nós (computadores) que trabalham em paralelo para processá-los.
Isso torna o Hadoop ideal para aplicações que precisam processar grandes quantidades de dados, como análises de mercado, análises climáticas e outras aplicações de inteligência artificial.
O Hadoop também é escalável, ou seja, ele pode ser facilmente adaptado para um ambiente em constante mudança. Se você precisar processar mais dados do que o seu cluster atual pode suportar, basta adicionar mais nós ao seu cluster.
Neste artigo, vamos mostrar como o Hadoop pode ser usado na área de ciência de dados. Vamos começar mostrando como instalar o Hadoop e configurá-lo para trabalhar com os dados. Em seguida, vamos ver alguns exemplos de aplicações da área de ciência de dados que podem ser facilmente implementadas usando o Hadoop.
Como instalar e configurar o Hadoop?
Para instalar e configurar o Apache Hadoop corretamente, é necessário seguir alguns passos básicos de configuração:
Primeiro, você precisa realizar o download do software Apache Hadoop da página oficial. A próxima etapa é iniciar a configuração, que envolve configurar as variáveis de ambiente e o armazenamento de arquivos (HDFS). Além disso, você também deve configurar o MapReduce, que é a tecnologia de computação distribuída utilizada pelo Hadoop. Após configurar os arquivos, é necessário fazer um teste a fim de certificar que o Apache Hadoop está corretamente instalado e configurado.
Por fim, é possível melhorar a performance do Apache Hadoop com alguns ajustes adicionais. Estes incluem a optimização do uso da memória, a configuração do algoritmo de balanceamento de carga, otimizando também o desempenho dos mapeadores e os redutores. Além disso, vale a pena configurar o recurso de segurança oferecido pelo Apache Hadoop.
Seguindo estes passos, é possível configurar completamente o Apache Hadoop e obter maior desempenho na computação de Big Data. Caso fique com alguma dúvida, no final do artigo está disponibilizado o link para a documentação do Apache Hadoop.
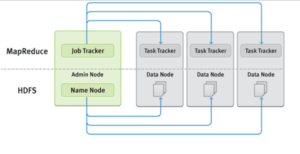
Componentes do Apache Hadoop
O framework do Hadoop é composto por dois módulos principais: o módulo de armazenamento e o de processamento.
O primeiro é denominado HDFS (Hadoop Distributed File System) e gerencia o armazenamento de dados entre as máquinas em que o cluster do Hadoop está sendo executado. Já o segundo, é a implementação do algoritmo do Map-Reduce e é responsável por gerir toda a parte de processamento do framework.
Porque Apache Hadoop é eficiente para Ciência de Dados?
O Hadoop permite que mais recursos computacionais sejam usados para processar dados, o que o torna muito eficiente para tarefas de Data Science. É importante lembrar que mesmo que outros sistemas possam processar grandes conjuntos de dados, o Hadoop oferece a flexibilidade de processar dados em vários nós em simultâneo, o que o torna extremamente eficiente e útil para tarefas de Ciência de dados. O Hadoop também oferece a capacidade de lidar com falhas, pois todos os dados são replicados automaticamente. Isso significa que os dados podem ser recuperados facilmente mesmo se um nó falhar.
O Apache Hadoop também oferece suporte a ambientes heterogêneos, permitindo que vários sistemas possam se comunicar e trabalhar juntos. Ele é projetado para suportar múltiplos formatos de dados e trabalhar com vários sistemas de arquivos. Isto torna o Hadoop ideal para uma ampla variedade de usos e para todas as tarefas de Ciência de Dados.
Qual a linguagem do Hadoop?
O Java oferece muitas vantagens sobre outras linguagens de programação, como a capacidade de criar aplicativos personalizados para processar dados, a possibilidade de compilar código para qualquer sistema operacional e a capacidade de usar linguagens de programação populares, como C, C ++ e Perl.
O Apache Hadoop se beneficia da linguagem Java porque a plataforma é muito escalável, permitindo que usuários adicionem mais hardware e software para aumentar a capacidade de processamento.
Exemplos de aplicações de Hadoop para Ciência de dados
Existem muitos exemplos de aplicações da tecnologia Hadoop em Ciência de dados, como Apache Pig, Apache Hive, Apache Flume, Apache Oozie, Apache HBase, Apache Spark, Apache Kafka e muito mais.
- Apache Pig é uma linguagem de processamento de dados estruturados;
- Apache Hive é uma plataforma de processamento de dados não estruturados;
- Apache Flume é usado para coletar, enfileirar e transportar grandes conjuntos de dados;
- Apache Oozie é usado para agendar processos petabyte escala;
- Apache HBase é usado para fornecer recursos de persistência, autenticação e autorização de dados.
- Apache Spark e Apache Kafka são usados para processar e transformar grandes conjuntos de dados em tempo real.
Como os cientistas de dados usam o Hadoop?
Os cientistas de dados podem utilizar para processar grandes volumes de dados, como dados meteorológicos, dados financeiros, dados de redes sociais e dados de sensoriamento. Um dos casos de uso mais comuns é para análises de logs de sites. Por exemplo, muitas empresas usam o Hadoop para processar o log de seus sites e recuperar informações importantes, como a localização dos usuários, o que os usuários estão procurando e outras informações que ajudam as empresas a melhorar seus produtos e serviços.
Além disso, o Hadoop é usado para análises de texto e linguística. Isso torna mais fácil para os cientistas de dados extraírem informações significativas de grandes conjuntos de dados. Por exemplo, ele pode ser usado para analisar grandes conjuntos de dados de mídia social, como tweets, para extrair sentimentos ou informações sobre a saúde de um determinado assunto. O Hadoop também pode ser usado para processamento de linguagem natural, como reconhecer palavras e frases, encontrar padrões e gerar novas palavras.
Se você está enfrentando dificuldades na utilização do Hadoop para processar seus dados, não se preocupe. A Mindtek tem uma equipe especializada em ajudar clientes a utilizar o Hadoop de forma eficiente e adequada às suas necessidades. Entre em contato conosco através do e-mail contato@mindtek.com.br e teremos prazer em ajudá-lo.
Confira artigos relacionados:

10 destaques do Qlik Cloud no mês de maio/2026
O Qlik Cloud segue evoluindo em um ritmo acelerado e as

Migração de dados entre sistemas: por que ela é decisiva para o futuro da sua empresa?
Imagine que a sua empresa cresce e precisa adotar um novo sistema

Power BI Desktop: quais são os requisitos mínimos para instalação?
Antes de começar a fazer dashboards, relatórios e análises